|
Smartphone-Based Invoice Scanning
|
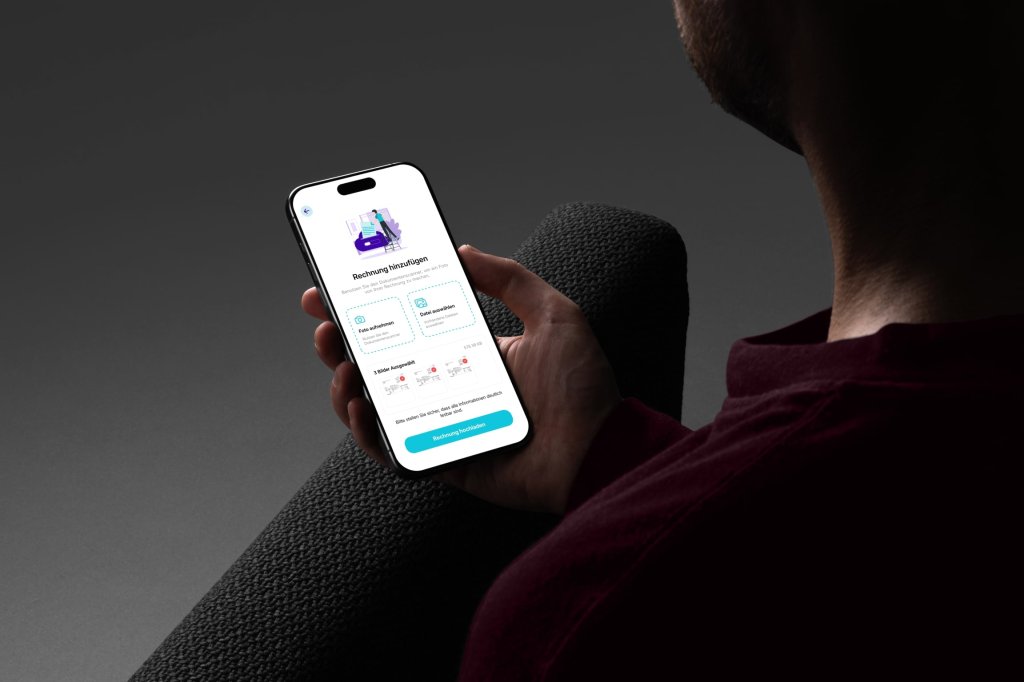
Use the smartphone camera to capture high-quality, optimized images of physical invoices. Achieved by an Invoice Scanning SDK from an EU vendor. It detects documents, enhances scan quality and ensures OCR accuracy.
|
|
Optical Character Recognition (OCR) Pipeline
|
Using open-source OCR solution to be used on-premise on Germany-based servers, to remain fully compliant with GDPR. Extracts key metadata.
|
|
Large Language Model (LLM) Integration
|
Locally hosted LLM parses OCR-extracted metadata and enhances data accuracy and context understanding.
|
|
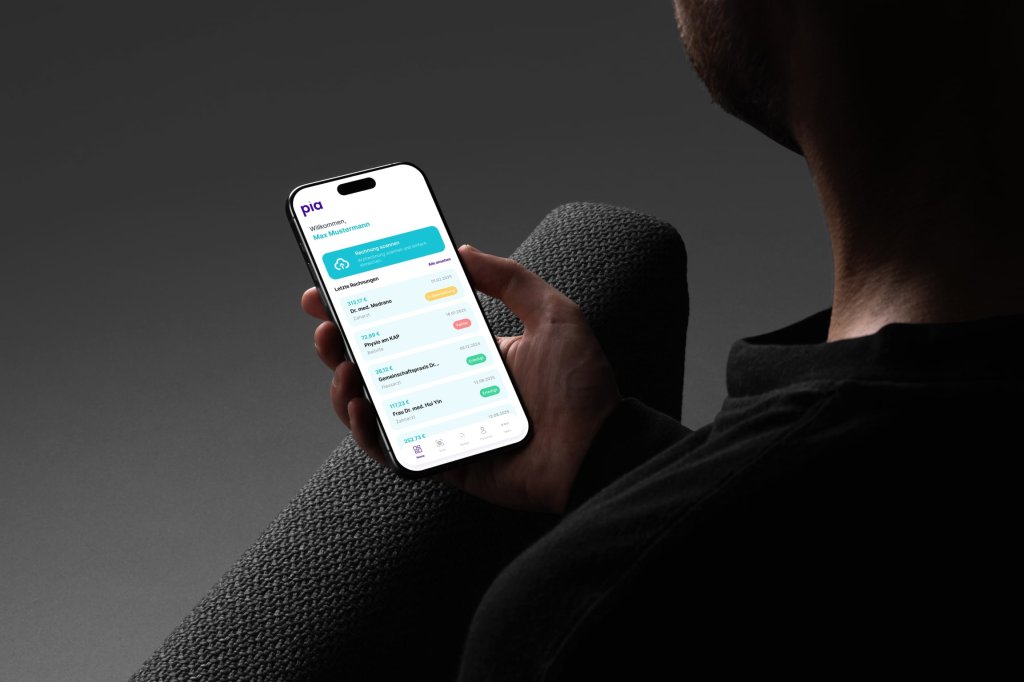
PDF Generation, Email Dispatch and Push Notifications
|
Auto-generated clean, structured PDF invoices and automatically sends them via email to health insurers. Supports push notifications when the app is installed.
|
|
Practitioner-Patient Connection Interface
|
Matching metadata accuracy from practitioner to user / patient. Initiated requests secure connections with practitioners, who can then upload documents directly to the patient’s account. Fully GDPR-compliant.
|
|
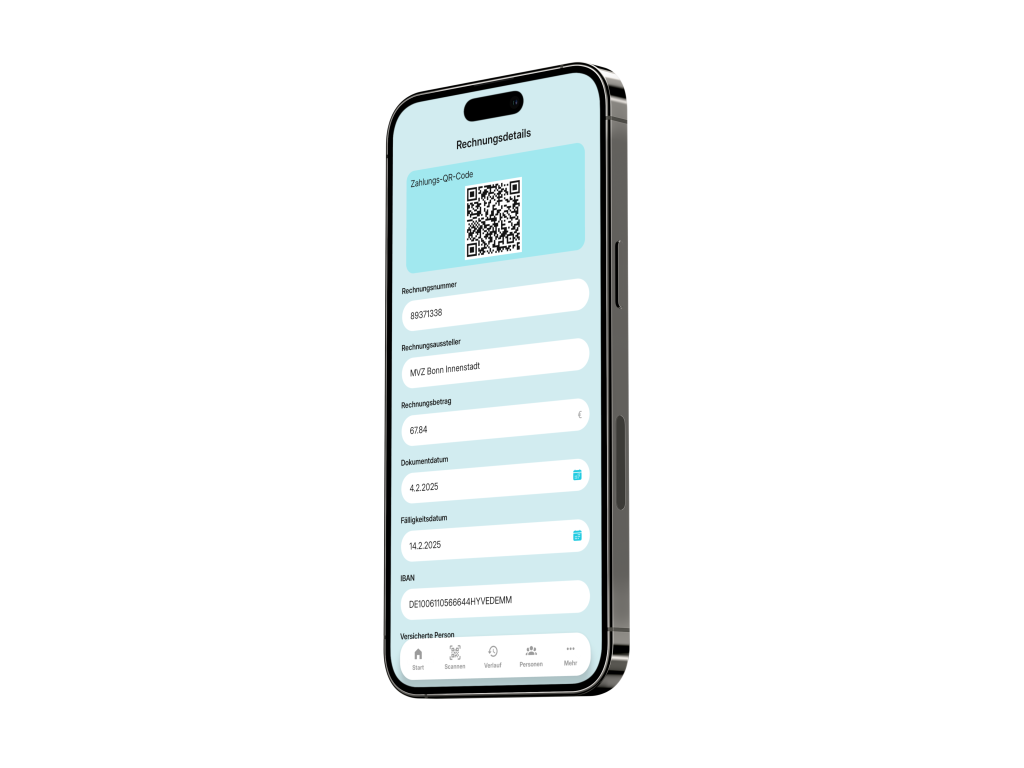
SEPA QR Code Payment Support
|
Generates SEPA-compliant QR codes for direct bank transfers.
|