ETL-Prozesse und Middleware: Wie Sie Datenflüsse zwischen Ihren Systemen automatisieren
Ihre Systeme sprechen nicht miteinander? Bestellungen müssen manuell vom Shop ins ERP übertragen werden? Kundendaten existieren in drei verschiedenen Tools? ETL-Prozesse (Extract, Transform, Load) lösen genau dieses Problem – sie automatisieren den Datenfluss zwischen Ihren Anwendungen und eliminieren manuelle Übertragungsfehler.


ETL steht für Extract, Transform, Load – ein Verfahren, das Daten automatisch aus einem System extrahiert, in das richtige Format umwandelt und in ein Zielsystem überträgt. Wenn zwei Ihrer Systeme keine fertige Integration haben, ist ein individueller ETL-Prozess oft die zuverlässigste und wirtschaftlichste Lösung.
Als Unternehmer nutzen Sie vermutlich mehrere digitale Werkzeuge: ein CRM-System, eine Buchhaltungssoftware, einen Online-Shop, vielleicht ein ERP. Etablierte Systeme wie HubSpot, Pipedrive oder Xentral bieten Integrationen für Standard-Anwendungsfälle. Aber was, wenn Ihr bevorzugtes Tool nicht dabei ist? Oder wenn die vorhandene Integration nicht das tut, was Sie brauchen?
Genau hier kommen ETL-Prozesse ins Spiel – und genau hier liegt einer unserer Schwerpunkte als Agentur für Automatisierung.
Was ist ein ETL-Prozess – und was ist eine Middleware?
ETL beschreibt ein dreistufiges Verfahren zur automatisierten Datenübertragung zwischen Systemen.
Extract: Daten werden aus einem Quellsystem gelesen – über eine API, eine Datenbank oder eine Datei (CSV, XML, JSON). Dabei wird entweder der komplette Datenbestand abgerufen (Full Extract) oder nur die seit dem letzten Lauf geänderten Daten (Incremental Extract).
Transform: Die extrahierten Daten werden in das Format umgewandelt, das das Zielsystem erwartet. Das kann einfach sein – etwa ein Datumsformat anpassen – oder komplex: Daten bereinigen, Duplikate entfernen, Geschäftsregeln anwenden, fehlende Felder ergänzen.
Load: Die transformierten Daten werden in das Zielsystem geschrieben – als neue Datensätze, als Update bestehender Einträge oder als vollständiger Ersatz.
In dieser Funktion arbeitet der ETL-Prozess als Middleware – eine Zwischenschicht, die zwei Systeme verbindet und den Datenaustausch über eine einheitliche Schnittstelle ermöglicht. Das ist besonders wertvoll, wenn die beteiligten Systeme unterschiedliche Datenformate, Authentifizierungsmethoden oder API-Standards verwenden.
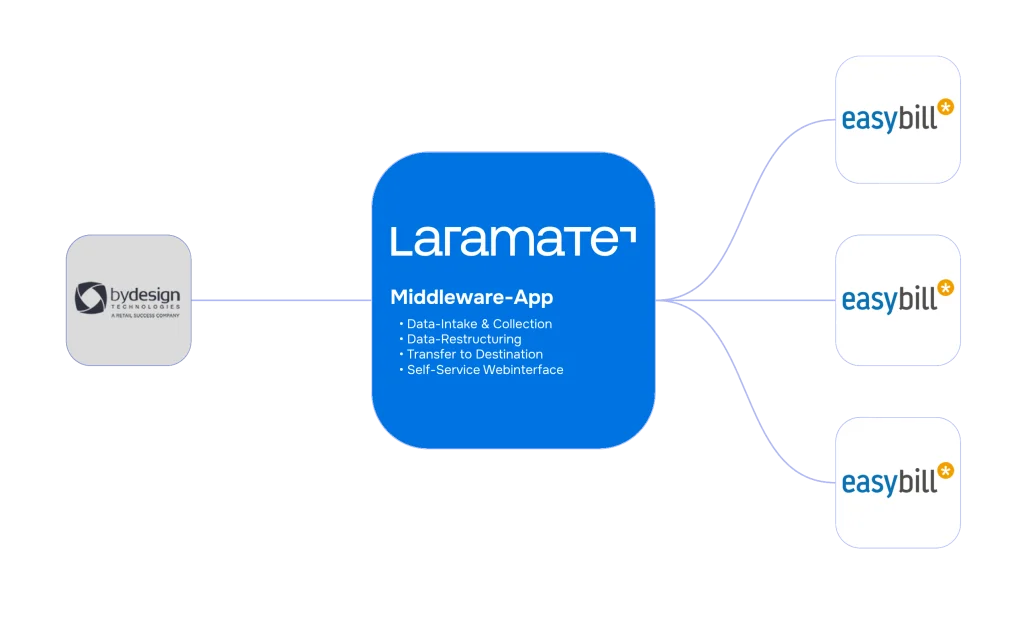
Wann brauchen Sie einen ETL-Prozess?
Immer dann, wenn zwei Systeme nicht direkt miteinander kommunizieren können – oder wenn die vorhandene Integration nicht ausreicht.
Typische Szenarien aus unserer Projektarbeit:
Shop → Buchhaltung: Bestellungen aus Shopify oder WooCommerce automatisch an Easybill oder lexoffice übertragen und Rechnungen generieren
CRM → E-Mail-Marketing: Neue Kontakte aus Pipedrive automatisch in die passende Mailchimp-Kampagne einordnen – basierend auf Branche, Produkt oder Lead-Score
Marketplace → ERP: Bestelldaten von einem Online-Marktplatz in das interne Warenwirtschaftssystem synchronisieren
Legacy-System → Neue Software: Daten aus einer Altanwendung in ein modernes System migrieren – einmalig oder als laufende Synchronisation
Sensordaten → Dashboard: IoT-Daten oder Kamerabilder verarbeiten und in einer Webanwendung visualisieren – wie in unserer OCR-basierten Parkraumverwaltung
Reicht nicht auch Zapier oder Make?
Für einfache Automatisierungen: Ja. Für geschäftskritische Datenflüsse: Meistens nicht.
No-Code-Tools wie Zapier, Make oder n8n sind hervorragend für einfache Workflows: "Wenn ein neuer Kontakt in HubSpot angelegt wird, erstelle einen Eintrag in Google Sheets." Aber sie stoßen an Grenzen, wenn:
Komplexe Geschäftslogik angewendet werden muss (Preisberechnungen, Rabattregeln, mehrstufige Validierung)
Große Datenmengen verarbeitet werden (Tausende Datensätze pro Lauf)
Fehlerbehandlung und Retry-Logik geschäftskritisch sind
Laufende Kosten durch pro-Task-Abrechnung explodieren
Die Daten Ihr Unternehmen nicht über einen Drittanbieter-Server verlassen sollen
In diesen Fällen ist eine individuelle ETL-Lösung auf Basis von Laravel die zuverlässigere und langfristig günstigere Wahl. Mehr dazu in unserem Vergleich No-Code vs. individuelle Softwareentwicklung.
Wie sieht ein ETL-Prozess in der Praxis aus?
Am besten lässt sich ETL an einem konkreten Beispiel erklären.
Nehmen wir eine Aufgabe, die wir in ähnlicher Form für mehrere Kunden umgesetzt haben: "Bestellungen von einem Online-Marktplatz automatisch in die Buchhaltungssoftware übertragen und Rechnungen generieren."
1. Extract: Die ETL-Anwendung fragt regelmäßig (z. B. alle 15 Minuten) die API des Marktplatzes ab und ruft neue Bestellungen ab. Dabei wird gespeichert, welche Bestellungen bereits verarbeitet wurden, um Duplikate zu vermeiden.
2. Transform: Die Bestelldaten werden in das Format der Buchhaltungssoftware umgewandelt: Artikelnummern werden zugeordnet, Steuersätze berechnet, Kundendaten abgeglichen oder neu angelegt. Geschäftsregeln entscheiden, ob eine Rechnung sofort erstellt oder erst nach Versand generiert wird.
3. Load: Die transformierten Daten werden über die API der Buchhaltungssoftware (z. B. Easybill) als Rechnung angelegt. Bei Fehlern – etwa einer ungültigen Steuernummer – wird der Datensatz markiert und eine Benachrichtigung ausgelöst.
Genau diesen Prozess haben wir in unserer Data Pipeline von BrickOwl nach Easybill umgesetzt – eine vollautomatische Rechnungsstellung für einen E-Commerce-Kunden. Ähnlich funktioniert unsere automatische Rechnungsstellung für ByDesign E-Commerce.
Warum eignet sich Laravel besonders für ETL-Prozesse?
Weil Laravel alles mitbringt, was ein zuverlässiger ETL-Prozess braucht – ohne dass Sie zusätzliche Infrastruktur aufbauen müssen.
Queues und Jobs: Datenverarbeitung im Hintergrund, ohne die Anwendung zu blockieren. Fehlgeschlagene Jobs werden automatisch wiederholt.
Scheduled Commands: ETL-Läufe können zeitgesteuert ausgeführt werden – alle 5 Minuten, stündlich oder täglich.
HTTP Client: Eingebauter HTTP-Client für API-Kommunikation mit Retry-Logik, Timeouts und Authentifizierung.
Notifications: Automatische Benachrichtigungen per E-Mail, Slack oder Webhook, wenn ein ETL-Lauf fehlschlägt.
Horizon: Dashboard zur Überwachung aller laufenden Jobs – Sie sehen in Echtzeit, welche Daten verarbeitet werden und wo Fehler auftreten.
FilamentPHP als Middleware-Dashboard: Mit FilamentPHP bauen wir individuelle Dashboards, die Transparenz über alle Datenströme liefern: Welche Datensätze wurden verarbeitet, welche stehen aus, wo gab es Fehler? So behalten Sie und Ihr Team den Überblick – ohne in Log-Dateien oder Datenbanktabellen suchen zu müssen.
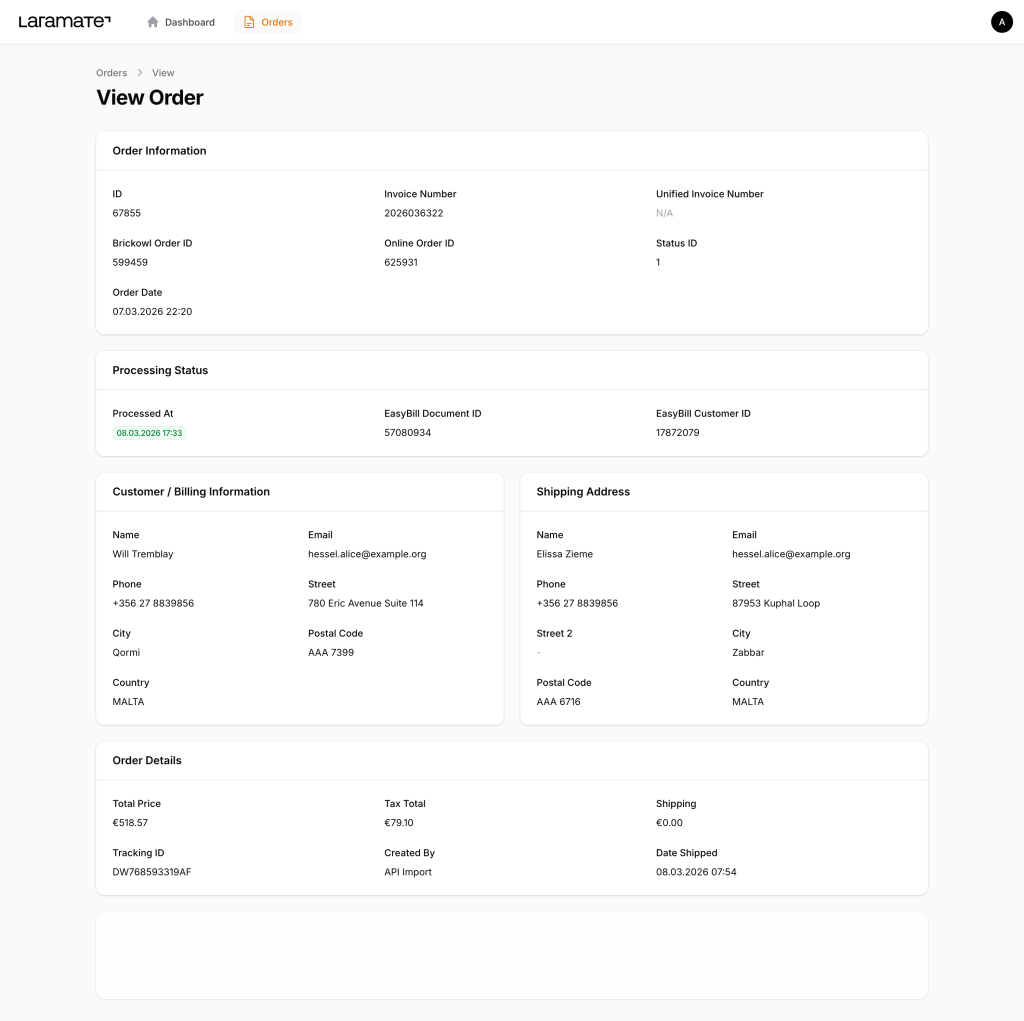
Das Ergebnis: Ein ETL-System, das nicht nur Daten überträgt, sondern sich selbst überwacht, Fehler behandelt und Ihnen über ein visuelles Dashboard volle Transparenz bietet. Mehr über unseren Ansatz erfahren Sie auf unserer Seite zu API-Entwicklung und Automatisierung.
Was kostet ein individueller ETL-Prozess?
Weniger als die meisten erwarten – und deutlich weniger als die Kosten manueller Datenübertragung.
Ein einfacher ETL-Prozess (eine Quelle, ein Ziel, klare Datenstruktur) ist in wenigen Tagen umsetzbar. Komplexere Szenarien mit mehreren Quellen, Geschäftslogik und Fehlerbehandlung dauern länger – aber die Investition amortisiert sich durch eingesparte Arbeitszeit und vermiedene Fehler oft innerhalb weniger Monate.
Vergleichen Sie: Wie viele Stunden pro Woche verbringen Ihre Mitarbeiter heute mit dem manuellen Übertragen von Daten zwischen Systemen? Wie oft entstehen dabei Fehler, die wieder korrigiert werden müssen? Diese versteckten Kosten sind der eigentliche Treiber – nicht die Entwicklung der Automatisierung. Mehr dazu in unserem Make-or-Buy-Vergleich.
Wie geht es weiter?
Wenn Ihre Systeme nicht miteinander sprechen und manuelle Datenübertragung Ihren Alltag bestimmt, ist ein ETL-Prozess die Lösung. Als Laravel-Agentur haben wir ETL-Systeme für verschiedenste Branchen umgesetzt – von der automatischen Rechnungsstellung bis zur Bild-Pipeline für Parkraummanagement.
Sprechen Sie mit uns – in einem unverbindlichen Erstgespräch analysieren wir Ihre aktuellen Datenflüsse und zeigen, wo Automatisierung den größten Hebel hat.
